The Classical Backpropagation Through Time Factorization
TL;DR A derivation of the "classical" factorization of the loss gradient in backpropagation through time mentioned in Bellec et al 2020.
The following will be well known to many, but I found it surprisingly hard to find on the internet. Here we derive what is referred to as the "classical factorization" of the loss gradient in backpropagation through time, which serves as the starting point for the derivation of the recently proposed "e-prop" learning rule (Murray 2019, Bellec et al 2020), which connects loss gradients in machine learning to biologically plausible, local plasticity rules.
Mostly, I thought it was worth writing a post about this to clarify exactly what they're talking about, and at the very least so that more than simply Bellec et al 2020 comes up in an internet search for "classical factorization of backpropagation through time".
Gradient of the loss with respect to weights in a recurrent neural network
Assume that a loss function E depends on a set of hidden states {ht} of a recurrent neural network parameterized by a weight matrix W. The "classical" factorization of the loss gradient ∇WE is defined via
dEdWji=∑tdEdhtj∂htj∂Wjiwhere j indexs the post-synaptic neuron. We'll ignore this index j (it essentially means that a specific weight only affects the loss through the neuron it projects onto), and instead focus on the factorization
dEdW=∑tdEdht∂ht∂Wwhich captures the essence of the problem in its fully vectorial format. Note that the first term is a total derivative whereas the second term is a partial derivative.
At the end of the day, the derivation boils down to the multivariate chain rule, but unfortunately if you just start plugging and chugging, it's easy to get lost and deviate away from this particular "factorization". For instance, you might start by summing up the partials of E with respect to ht multiplied by the total derivatives of ht with respect to W
dEdW=∑t∂E∂htdhtdW.If you treat ht and W as scalars and assume that E=E({ht}) and ht=ht(W), this is exactly what you would have learned to do in multivariate calculus class. But if we compare this to the "classical factorization" the partial and total derivatives are reversed! How can we recover the classical factorization without getting lost in a sea of derivatives?
The key, of course, is to think in terms of computation graphs, one of the abstractions that has made modern machine learning what it is today.
Computation graphs and the chain rule
Essentially, computation graphs are directed acyclic graphs that specify how information flows through a computation, and they are super useful for computing gradients in complex computations. See Christopher Olah's excellent blog post for details about how they work. For example, we can depict the set of functions
x=x(W)y=y(x,W)z=z(y,W)L=L(x,y,z)
as
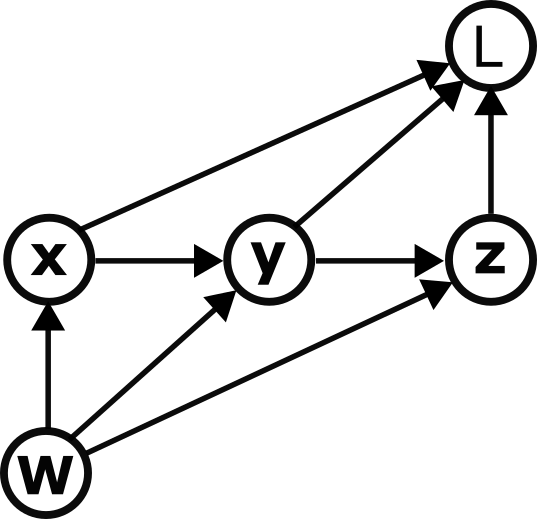 .
.
Now, if we wanted to figure out the gradient of L with respect to W we could crunch through the chain rule. However, there's a good chance we'd get lost or end up with a bunch of decisions to make about how to group terms to keep everything from getting out of control.
Summing over paths to compute derivatives
Enter the computation graph, which makes everything immensely easier. The rule for computing the total derivative of one node B with respect to an ancestor node A is very simple: sum up all of the paths from A to B. (The total derivative specifies the change in B caused by a change in A through all possible other variables through which A could influence B.) Stated more precisely, the sum is indeed a sum over paths, where each "path" is represented mathematically as the product of Jacobians going backward along the path.
For example, to calculate the total derivative dL/dW we first enumerate all six paths from W to L:
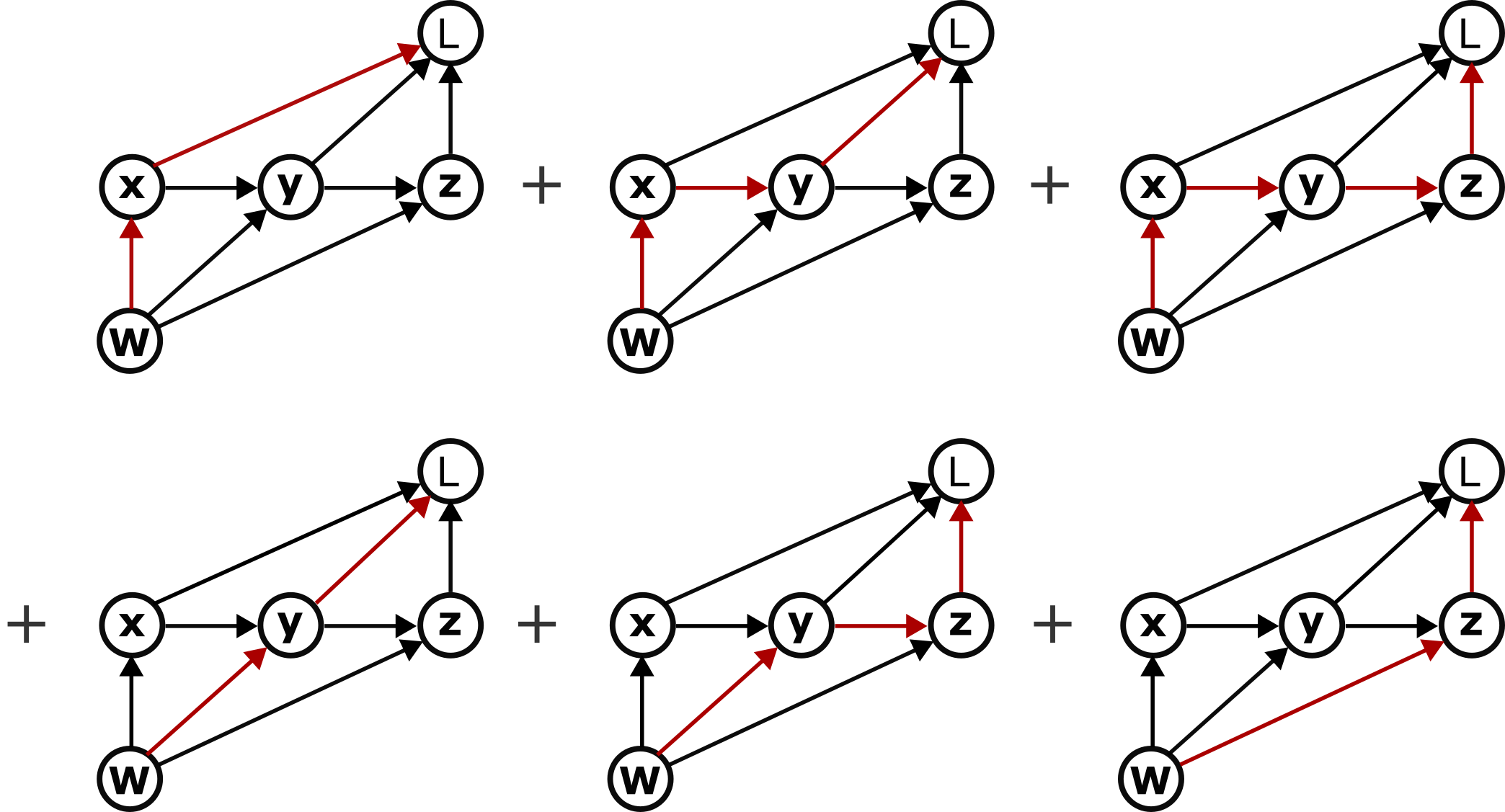 and then sum them via:
and then sum them via:
where DBA is the Jacobian of B with respect to A. Recall that the Jacobian is the matrix of partial derivatives of each component of B with respect to each component of A, whose dimension is dim(B)×dim(A).
Factorizing sums of paths
We still need one more trick, however. Counting paths can also get out of hand pretty quickly. Luckily, however, we can factorize these sums, essentially by identifying which terms have common Jacobians and applying the distributive rule. There are various ways to do this, but one that will be particularly useful in our case is to group the first three terms together, then the next two terms, then the final term:
dLdW=(DLxDxW+DLyDyxDxW+DLzDzyDyxDxW)+(DLyDyW+DLzDzyDyW)+DLzDzW=(DLx+DLyDyx+DLzDzyDyx)DxW+(DLy+DLzDzy)DyW+DLzDzW.Here we have organized the set of paths by grouping the paths according to which of them share a common edge from W to one of the intermediate nodes. We can in turn notice that the left hand term in each product is in fact a total derivative:
dLdW=dLdxDxW+dLdyDyW+dLdzDzW.We have almost arrived at the classical factorization of BPTT!
Return to backpropagation through time
The computation graph for a recurrent neural network with hidden states ht and parameterized by weights W is:
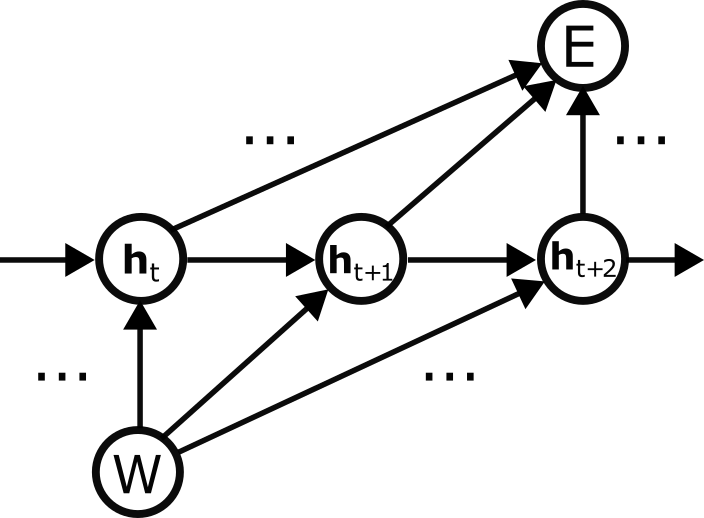
We will now factorize the gradient of the loss E with respect to the weights W. As with the last example, we will group terms according to the first edge out of W:
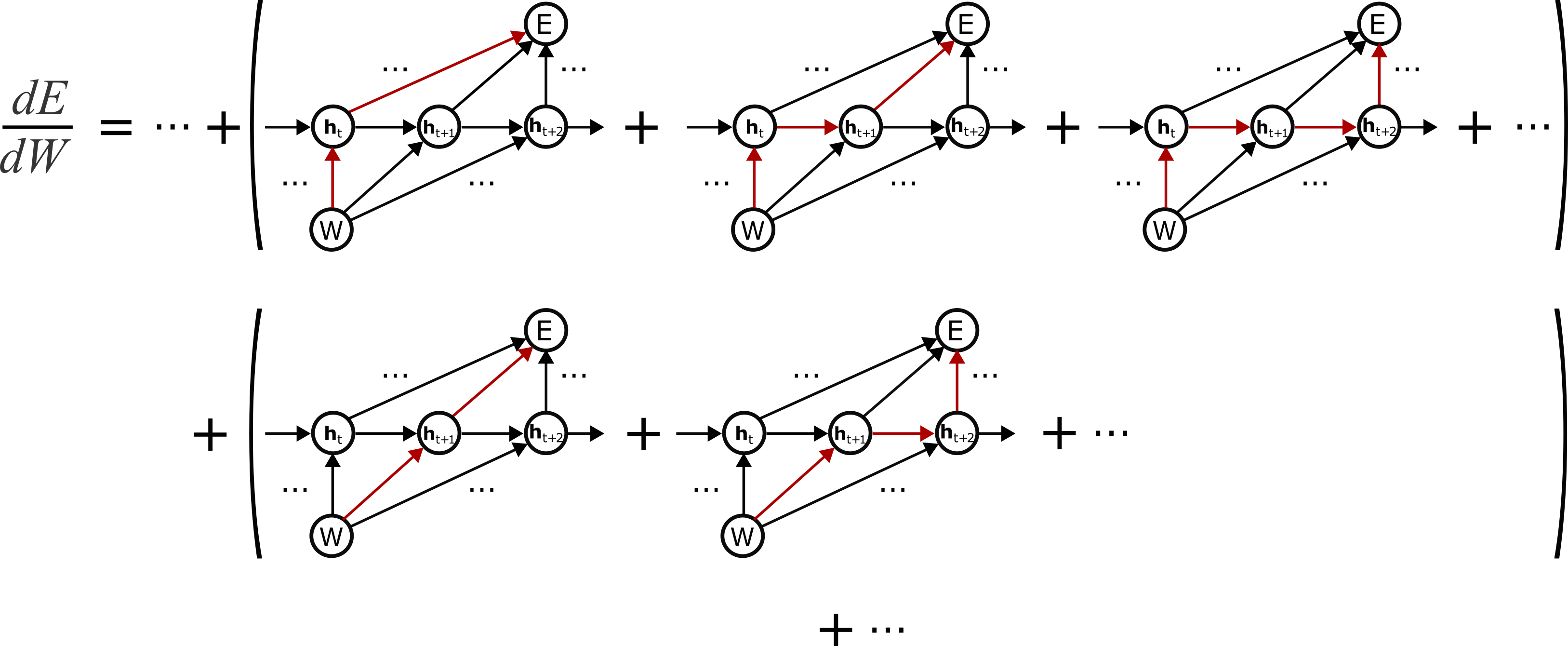 or, mathematically:
or, mathematically:
where we replaced the left-hand terms with their corresponding total derivatives (since they specify all paths from ht<\span> to E. Finally, recalling that the Jacobian is a matrix of partial derivatives, we arrive at
dEdW=∑tdEdht∂ht∂Wrecovering the classical factorization.